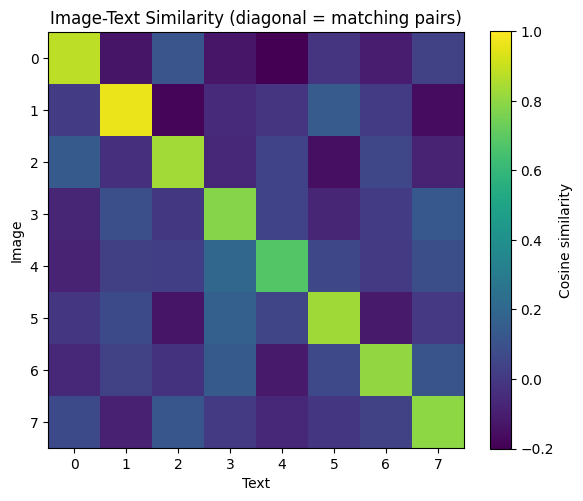
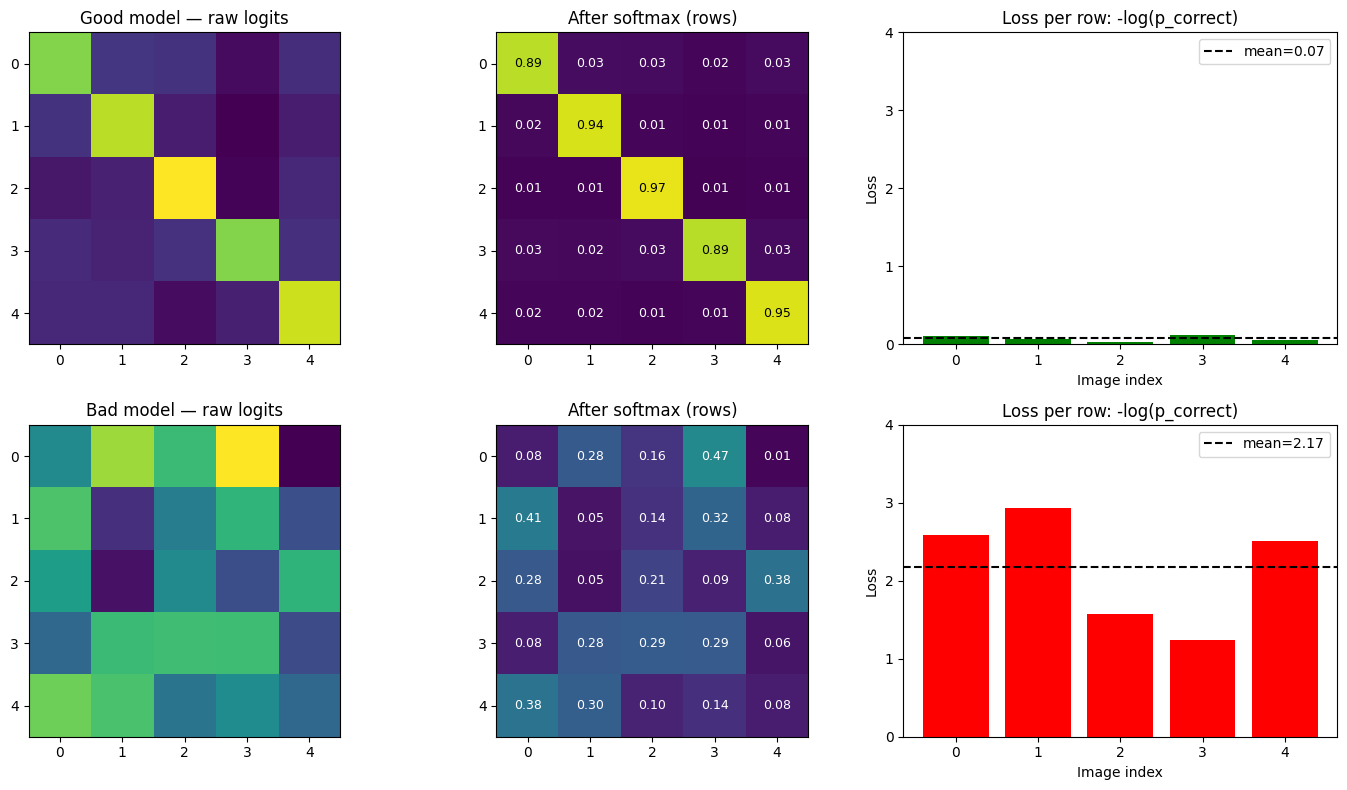
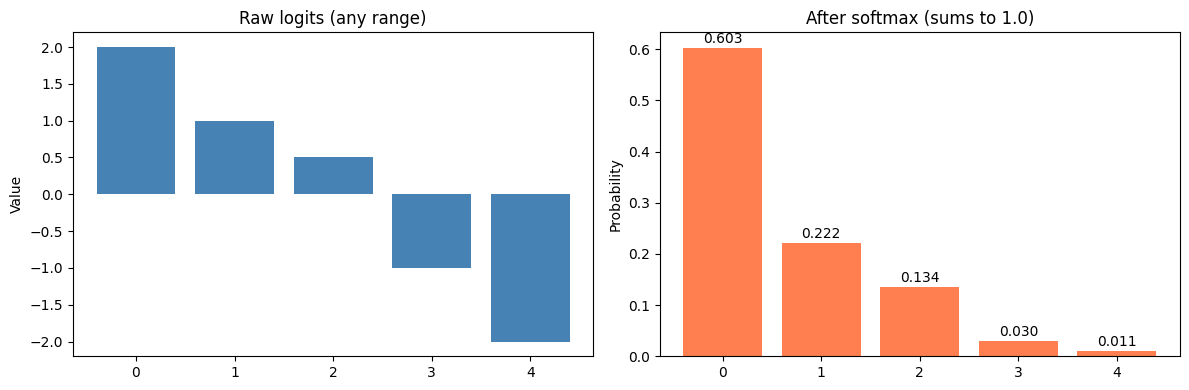
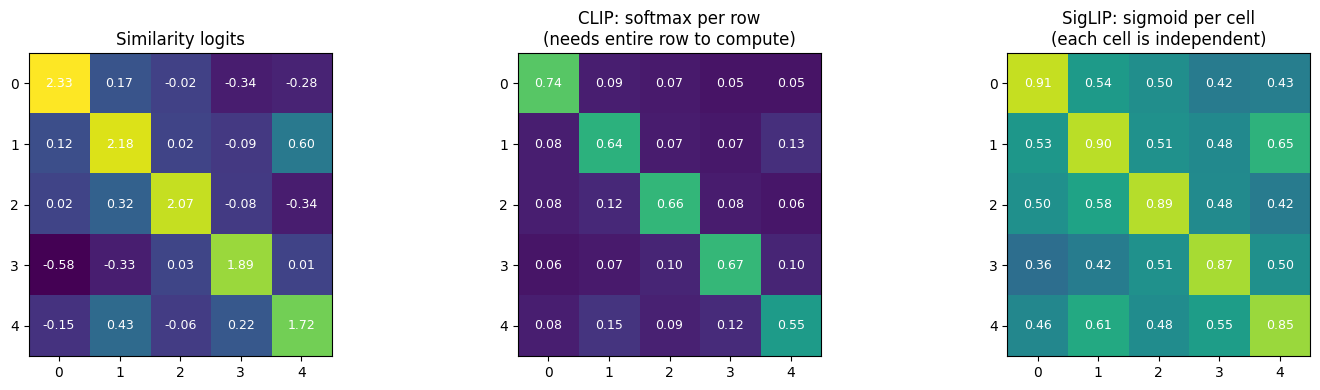
class SiglipAttention(nn.Module):
# no causal mask like language models.
# start with a sequence of patches, each represented by a 1x1024 vector.
# each patch is from a group of pixels.
# the resulting attnetion maks now has information about the patches realtionship to other patches.
# in language, we contextualize the token against all the tokens that came _before_ it. slight difference than in vit.
# we use causal mask for next-token prediction task. transformer lets us do that in parallel. hence the causal mask.
def __init__(self, config: SiglipVisionConfig):
super().__init__()
self.config = config
self.embed_dim = config.hidden_size
self.num_heads = config.num_attention_heads
self.head_dim = self.embed_dim // self.num_heads
self.scale = self.head_dim ** -0.5 # self.embed_dim ** -0.5 precomputes that 1/√d_k divisor as a multiplier for efficiency.
self.dropout = config.attention_dropout
self.q_proj = nn.Linear(self.embed_dim, self.embed_dim)
self.k_proj = nn.Linear(self.embed_dim, self.embed_dim)# parameter matrices that transform input squences,shape stays the same
self.v_proj = nn.Linear(self.embed_dim, self.embed_dim)
self.out_proj = nn.Linear(self.embed_dim, self.embed_dim) # W_o matrix
def forward(self, hidden_states: torch.Tensor ) -> Tuple[torch.Tensor, Optional[torch.Tensor]]:
# [Batch_Size, Num_Patches, Embed_Dim] you can think o fnum_patches as the sequence length.
batch_size, seq_len, _ = hidden_states.size()
#[Batch_Size, Num_Patches, Embed_Dim]
query_states = self.q_proj(hidden_states)
#[Batch_Size, Num_Patches, Embed_Dim]
key_states = self.k_proj(hidden_states)
#[Batch_Size, Num_Patches, Embed_Dim]
value_states = self.v_proj(hidden_states)
# head splitting here
query_states = query_states.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
# the view splits the last dimension into
# [Batch_Size, Num_Patches, Num_Heads, Head_Dim] 1024/8 for example will be 128. So each head receives 128
# the transpose then changes to #[Batch_Size, Num_Heads, Num_Patches, Head_Dim]
# why transpose? [1, 4, 8, 128] -> [1, 8, 4, 128] for example. So think of it as one big matrix, with 8 smaller matrices, one going into each head.
# once its transposed, we can paralleize better. each head has a sequence of 4 tokens x 128. each head can be treated independently basically.
key_states = key_states.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
#[Batch_Size, Num_Heads, Num_Patches, Head_Dim]
value_states = value_states.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
#[Batch_Size, Num_Heads, Num_Patches, Head_Dim]
# in our vit.py attn = torch.matmul(q, k.transpose(-1, -2)) * self.scale
# calucalte the attention using Q * K^T /sqrt(d_k). These will now be [Batch_Size, Num_Heads, Num_Patches, Num_Patches]
attn_weights = (torch.matmul(query_states, key_states.transpose(2, 3)) * self.scale)
if attn_weights.size() != (batch_size, self.num_heads, seq_len, seq_len):
raise ValueError(
f'Attention weights should be of size {(batch_size, self.num_heads, seq_len, seq_len)} but is'
f'{attn_weights.size()}'
)
# apply the softmax row-wise: [Batch_Size, Num_HEads, num_PAtches, num_PAtches]
attn_weights = nn.functional.softmax(attn_weights, dim =-1, dtype=torch.float32).to(query_states.dtype)
attn_weights = nn.functional.dropout(attn_weights, p = self.dropout, training = self.training)
# last part of the formula
# compute a weighted sum of softmaxed Q*K. Q*K should be 0 above the diagonal. So this is 'causal'
# so Q * K tells us how much each token will contribute to the final embedding, and by how much.
# each head is only looking at a part of the embeddings, and it will learn different attention scores
attn_output = torch.matmul(attn_weights, value_states)
if attn_output.size() != (batch_size, self.num_heads, seq_len, self.head_dim):
raise ValueError(
f"`attn_output` should be of size {(batch_size, self.num_heads, seq_len, self.head_dim)}, but is"
f" {attn_output.size()}"
)
# Transpose: [Batch, Num_Heads, Num_Patches, Head_Dim] → [Batch, Num_Patches, Num_Heads, Head_Dim]
attn_output = attn_output.transpose(1, 2).contiguous()
#this reshape is the concat operation!
# Reshape: [Batch, Num_Patches, Num_Heads, Head_Dim] → [Batch, Num_Patches, Embed_Dim]
attn_output = attn_output.reshape(batch_size, seq_len, self.embed_dim)
# [Batch_Size, Num_Patches, Embed_Dim]
#self.out_proj applies the final linear projection W_O on the concatenated result, matching the standard formula: Output =
#Concat(head_1, ..., head_h) · W_O.
attn_output = self.out_proj(attn_output)# we need this to mix between heads.
return attn_output, attn_weights
class SiglipMLP(nn.Module):
def __init__(self, config: SiglipVisionConfig):
super().__init__()
self.config = config
self.fc1 = nn.Linear(config.hidden_size, config.intermediate_size)
self.fc2 = nn.Linear(config.intermediate_size, config.hidden_size)
def forward(self, hidden_states: torch.Tensor ) -> torch.Tensor:
# [Batch_Size, Num_Patches, Embed_Dim] -> [Batch_Size, Num_Patches, Intermediate_Size]
hidden_states = self.fc1(hidden_states)
hidden_states = nn.functional.gelu(hidden_states, approximate='tanh')
# [Batch_Size, Num_Patches, Intermediate_Size] -> [Batch_Size, Num_Patches, Embed_Dim]
hidden_states = self.fc2(hidden_states)
return hidden_states